
Classifying Fakes News from Real News
In this blog post, I will build a fake news detector using TensorFlow word embedding and visualize the embedding using Plotly.
§1. Setup
First, we need to import all the necessary packages:
import numpy as np
import pandas as pd
import tensorflow as tf
import re
import string
from tensorflow.keras import layers
from tensorflow.keras import losses
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
from tensorflow.keras.layers.experimental.preprocessing import StringLookup
from tensorflow import keras
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
# for stopwords
from nltk.corpus import stopwords
# for embedding viz
import plotly.express as px
import plotly.io as pio
pio.templates.default = "plotly_white"
import matplotlib.pyplot as plt
Acquiring Training Data
Next, let’s go ahead and read in our training data and take a look at the dataset we have been given.
train_url = "https://github.com/PhilChodrow/PIC16b/blob/master/datasets/fake_news_train.csv?raw=true"
df = pd.read_csv(train_url)
df.head()
| Unnamed: 0 | title | text | fake | |
|---|---|---|---|---|
| 0 | 17366 | Merkel: Strong result for Austria's FPO 'big c... | German Chancellor Angela Merkel said on Monday... | 0 |
| 1 | 5634 | Trump says Pence will lead voter fraud panel | WEST PALM BEACH, Fla.President Donald Trump sa... | 0 |
| 2 | 17487 | JUST IN: SUSPECTED LEAKER and “Close Confidant... | On December 5, 2017, Circa s Sara Carter warne... | 1 |
| 3 | 12217 | Thyssenkrupp has offered help to Argentina ove... | Germany s Thyssenkrupp, has offered assistance... | 0 |
| 4 | 5535 | Trump say appeals court decision on travel ban... | President Donald Trump on Thursday called the ... | 0 |
We see that each row of the data corresponds to an article. The title column gives the title of the article, while the text column gives the full article text. The final column, called fake, is 0 if the article is true and 1 if the article contains fake news, as determined by the authors of the paper above.
§2. Make the Dataset
Our next step is to remove the stopwords from the title and text columns. A stopword is a word that is usually considered to be uninformative, such as “the,” “and,” or “but.”
To do this we first run the following code:
import nltk
nltk.download('stopwords')
stop = stopwords.words('english')
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
Now let’s construct and return a tf.data.Dataset with two inputs and one output. The input will be of the form (title, text), and the output will consist only of the fake column. We will also batch our data to help increase the speed of training.
def make_dataset(df):
'''
removes stopwords from df and then converts
the dataframe to a tf.data.dataset.
'''
# remove stopwords
df['title_without_stopwords'] = df['title'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))
df['text_without_stopwords'] = df['text'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))
# specify inputs and outputs of tf.data.dataset
my_data_set = tf.data.Dataset.from_tensor_slices(
( # dictionary for input data/features
{
"title" : df[["title_without_stopwords"]],
"text" : df[["text_without_stopwords"]]
},
# dictionary for output data/labels
{
"fake" : df[["fake"]]
}
)
)
my_data_set = my_data_set.batch(100)
return my_data_set
Split the Dataset
Now, let’s call our function and construct our dataset. Then we need to split it into train, validation, and test. This is done below, and 20% of our training data is set aside as validation data.
data = make_dataset(df)
# 70% train, 20% validation, 10% test
train_size = int(0.7*len(data))
val_size = int(0.2*len(data))
# get validation and training and test data
train = data.take(train_size) # data[:train_size]
val = data.skip(train_size).take(val_size) # data[train_size : train_size + val_size]
test = data.skip(train_size+val_size) # data[train_size + val_size:]
Base Rate
The base rate refers to the accuracy of a model that always makes the same guess (for example, such a model might always say “fake news!”). Now we need to determine the base rate for this data set by examining the labels on the training set.
#iterate through the labels on the training data
labels_iterator= train.unbatch().map(lambda text, fake: fake).as_numpy_iterator()
true = 0
fake = 0
for labels in labels_iterator:
#if label = 0, add to true
if labels['fake'] == 0:
true += 1
#if label = 1, add to fake
else:
fake += 1
print(str("Articles labeled as true:"), true)
print(str("Articles labeled as fake:"), fake)
#how often will the model identify an article as true
base_rate = fake / (true + fake)
base_rate = str(round(base_rate*100, 2))
print(str("The base model will predict 'fake'"), base_rate, str("% of the time."))
Articles labeled as true: 7483
Articles labeled as fake: 8217
The base model will predict 'fake' 52.34 % of the time.
There are 7,483 articles labeled as true. There are 8,217 articles labeled as fake. Thus, the base model will predict an article is ‘fake’ 52.34 % of the time.
§3. Create Models
Model 1
In the first model, we will use only the article title as an input.
We will also add the following code to vectorize our layers and format them so that we can adapt them for our models.
#preparing a text vectorization layer for tf model
size_vocabulary = 2000
def standardization(input_data):
lowercase = tf.strings.lower(input_data) # convert into lowercase
no_punctuation = tf.strings.regex_replace(lowercase,
'[%s]' % re.escape(string.punctuation),'')
# remove punctuation and some other elements
return no_punctuation
title_vectorize_layer = TextVectorization(
standardize=standardization,
max_tokens=size_vocabulary, # only consider this many words
output_mode='int',
output_sequence_length=500)
title_vectorize_layer.adapt(train.map(lambda x, y: x["title"]))
Our first model uses only the title of the articles to predict whether an article is fake or not. We will pass our title_input through the following layers and then predict the output using the following code.
title_input = keras.Input(
shape = (1,),
name = "title",
dtype = "string"
)
title_features = title_vectorize_layer(title_input) # apply the vectorization layer to the titles_input
title_features = layers.Embedding(size_vocabulary, output_dim = 3, name="embedding1")(title_features)
title_features = layers.Dropout(0.2)(title_features)
title_features = layers.GlobalAveragePooling1D()(title_features)
title_features = layers.Dropout(0.2)(title_features)
title_features = layers.Dense(32, activation='relu')(title_features)
title_features = layers.Dense(32, activation='relu')(title_features)
output = layers.Dense(2, name = "fake")(title_features)
model1 = keras.Model(
inputs = title_input,
outputs = output
)
Now we have to fit our model to our training set.
model1.compile(optimizer="adam",
loss = losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"])
history = model1.fit(train,
validation_data=val,
epochs = 50,
verbose = 1)
Epoch 1/50
/usr/local/lib/python3.7/dist-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['text'] which did not match any model input. They will be ignored by the model.
inputs = self._flatten_to_reference_inputs(inputs)
157/157 [==============================] - 2s 7ms/step - loss: 0.6924 - accuracy: 0.5181 - val_loss: 0.6928 - val_accuracy: 0.5164
Epoch 2/50
157/157 [==============================] - 1s 6ms/step - loss: 0.6919 - accuracy: 0.5234 - val_loss: 0.6917 - val_accuracy: 0.5164
Epoch 3/50
157/157 [==============================] - 1s 6ms/step - loss: 0.6334 - accuracy: 0.6839 - val_loss: 0.4596 - val_accuracy: 0.9216
Epoch 4/50
157/157 [==============================] - 1s 6ms/step - loss: 0.2796 - accuracy: 0.9297 - val_loss: 0.1559 - val_accuracy: 0.9533
Epoch 5/50
157/157 [==============================] - 1s 6ms/step - loss: 0.1474 - accuracy: 0.9535 - val_loss: 0.1025 - val_accuracy: 0.9667
Epoch 6/50
157/157 [==============================] - 1s 6ms/step - loss: 0.1153 - accuracy: 0.9611 - val_loss: 0.0838 - val_accuracy: 0.9720
Epoch 7/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0964 - accuracy: 0.9652 - val_loss: 0.0727 - val_accuracy: 0.9731
Epoch 8/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0884 - accuracy: 0.9694 - val_loss: 0.0677 - val_accuracy: 0.9764
Epoch 9/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0809 - accuracy: 0.9710 - val_loss: 0.0617 - val_accuracy: 0.9773
Epoch 10/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0743 - accuracy: 0.9728 - val_loss: 0.0584 - val_accuracy: 0.9782
Epoch 11/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0710 - accuracy: 0.9745 - val_loss: 0.0622 - val_accuracy: 0.9773
Epoch 12/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0686 - accuracy: 0.9750 - val_loss: 0.0543 - val_accuracy: 0.9800
Epoch 13/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0638 - accuracy: 0.9768 - val_loss: 0.0528 - val_accuracy: 0.9804
Epoch 14/50
157/157 [==============================] - 1s 9ms/step - loss: 0.0610 - accuracy: 0.9780 - val_loss: 0.0513 - val_accuracy: 0.9811
Epoch 15/50
157/157 [==============================] - 2s 10ms/step - loss: 0.0560 - accuracy: 0.9784 - val_loss: 0.0501 - val_accuracy: 0.9813
Epoch 16/50
157/157 [==============================] - 1s 10ms/step - loss: 0.0562 - accuracy: 0.9790 - val_loss: 0.0500 - val_accuracy: 0.9824
Epoch 17/50
157/157 [==============================] - 1s 7ms/step - loss: 0.0514 - accuracy: 0.9818 - val_loss: 0.0488 - val_accuracy: 0.9824
Epoch 18/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0534 - accuracy: 0.9803 - val_loss: 0.0490 - val_accuracy: 0.9824
Epoch 19/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0502 - accuracy: 0.9811 - val_loss: 0.0491 - val_accuracy: 0.9827
Epoch 20/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0504 - accuracy: 0.9803 - val_loss: 0.0538 - val_accuracy: 0.9813
Epoch 21/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0479 - accuracy: 0.9814 - val_loss: 0.0474 - val_accuracy: 0.9836
Epoch 22/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0456 - accuracy: 0.9828 - val_loss: 0.0474 - val_accuracy: 0.9833
Epoch 23/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0447 - accuracy: 0.9829 - val_loss: 0.0485 - val_accuracy: 0.9822
Epoch 24/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0440 - accuracy: 0.9824 - val_loss: 0.0473 - val_accuracy: 0.9831
Epoch 25/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0447 - accuracy: 0.9832 - val_loss: 0.0521 - val_accuracy: 0.9822
Epoch 26/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0448 - accuracy: 0.9829 - val_loss: 0.0473 - val_accuracy: 0.9833
Epoch 27/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0460 - accuracy: 0.9833 - val_loss: 0.0471 - val_accuracy: 0.9824
Epoch 28/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0447 - accuracy: 0.9823 - val_loss: 0.0486 - val_accuracy: 0.9833
Epoch 29/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0416 - accuracy: 0.9829 - val_loss: 0.0481 - val_accuracy: 0.9822
Epoch 30/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0413 - accuracy: 0.9846 - val_loss: 0.0492 - val_accuracy: 0.9822
Epoch 31/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0395 - accuracy: 0.9835 - val_loss: 0.0512 - val_accuracy: 0.9833
Epoch 32/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0423 - accuracy: 0.9829 - val_loss: 0.0501 - val_accuracy: 0.9831
Epoch 33/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0367 - accuracy: 0.9854 - val_loss: 0.0504 - val_accuracy: 0.9831
Epoch 34/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0374 - accuracy: 0.9860 - val_loss: 0.0610 - val_accuracy: 0.9811
Epoch 35/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0404 - accuracy: 0.9844 - val_loss: 0.0489 - val_accuracy: 0.9829
Epoch 36/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0327 - accuracy: 0.9873 - val_loss: 0.0511 - val_accuracy: 0.9836
Epoch 37/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0374 - accuracy: 0.9857 - val_loss: 0.0496 - val_accuracy: 0.9829
Epoch 38/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0382 - accuracy: 0.9846 - val_loss: 0.0539 - val_accuracy: 0.9833
Epoch 39/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0363 - accuracy: 0.9866 - val_loss: 0.0619 - val_accuracy: 0.9811
Epoch 40/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0384 - accuracy: 0.9852 - val_loss: 0.0503 - val_accuracy: 0.9829
Epoch 41/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0364 - accuracy: 0.9857 - val_loss: 0.0799 - val_accuracy: 0.9764
Epoch 42/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0359 - accuracy: 0.9859 - val_loss: 0.0505 - val_accuracy: 0.9833
Epoch 43/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0371 - accuracy: 0.9850 - val_loss: 0.0630 - val_accuracy: 0.9804
Epoch 44/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0354 - accuracy: 0.9861 - val_loss: 0.0509 - val_accuracy: 0.9831
Epoch 45/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0362 - accuracy: 0.9853 - val_loss: 0.0591 - val_accuracy: 0.9809
Epoch 46/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0346 - accuracy: 0.9873 - val_loss: 0.0551 - val_accuracy: 0.9811
Epoch 47/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0332 - accuracy: 0.9861 - val_loss: 0.0679 - val_accuracy: 0.9793
Epoch 48/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0316 - accuracy: 0.9876 - val_loss: 0.0606 - val_accuracy: 0.9813
Epoch 49/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0335 - accuracy: 0.9864 - val_loss: 0.0740 - val_accuracy: 0.9787
Epoch 50/50
157/157 [==============================] - 1s 6ms/step - loss: 0.0334 - accuracy: 0.9873 - val_loss: 0.0539 - val_accuracy: 0.9822
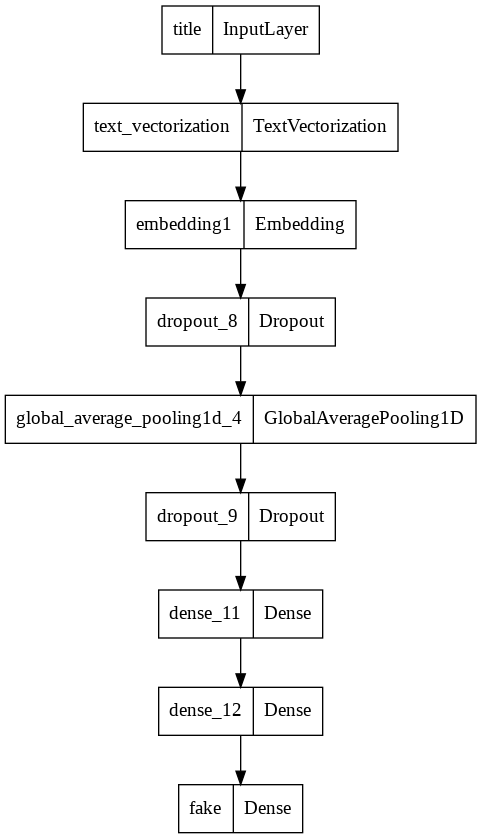
Let’s look at the flow of our model
from tensorflow.keras import utils
utils.plot_model(model1)
Finally, let’s plot its performance on the validation set.
def history_plot():
plt.plot(history.history["accuracy"], label = "training")
plt.plot(history.history["val_accuracy"], label = "validation")
plt.gca().set(xlabel = "epoch", ylabel = "accuracy")
plt.legend()
history_plot()
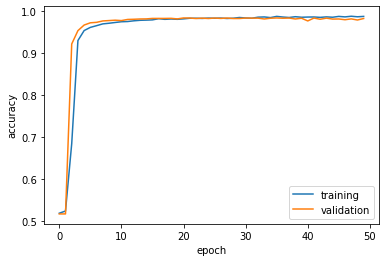
Looks like we got our model to have around a consistent 98% accuracy! Now let’s perform the same process but this time we will only use the text of the articles in our model.
Model 2
In the second model, we will use only the article text as an input.
Now, we will add the following code to vectorize our layers and format them so that we can adapt them for our models.
text_vectorize_layer = TextVectorization(
standardize=standardization,
max_tokens=size_vocabulary, # only consider this many words
output_mode='int',
output_sequence_length=500)
text_vectorize_layer.adapt(train.map(lambda x, y: x["text"]))
Our second model uses only the text of the articles to predict whether an article is fake or not.
text_input = keras.Input(
shape = (1,),
name = "text",
dtype = "string"
)
text_features = text_vectorize_layer(text_input) # apply the vectorization layer to the titles_input
text_features = layers.Embedding(size_vocabulary, output_dim = 10, name="embedding2")(text_features)
text_features = layers.Dropout(0.2)(text_features)
text_features = layers.GlobalAveragePooling1D()(text_features)
text_features = layers.Dropout(0.2)(text_features)
text_features = layers.Dense(32, activation='relu')(text_features)
text_features = layers.Dense(32, activation='relu')(text_features)
output = layers.Dense(2, name = "fake")(text_features)
model2 = keras.Model(
inputs = text_input,
outputs = output
)
Now we have to fit our model to our training set.
model2.compile(optimizer="adam",
loss = losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"])
history = model2.fit(train,
validation_data=val,
epochs = 50,
verbose = 1)
Epoch 1/50
/usr/local/lib/python3.7/dist-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['title'] which did not match any model input. They will be ignored by the model.
inputs = self._flatten_to_reference_inputs(inputs)
157/157 [==============================] - 2s 12ms/step - loss: 0.5829 - accuracy: 0.7111 - val_loss: 0.2748 - val_accuracy: 0.9389
Epoch 2/50
157/157 [==============================] - 2s 11ms/step - loss: 0.1767 - accuracy: 0.9497 - val_loss: 0.1298 - val_accuracy: 0.9618
Epoch 3/50
157/157 [==============================] - 2s 11ms/step - loss: 0.1096 - accuracy: 0.9697 - val_loss: 0.1011 - val_accuracy: 0.9689
Epoch 4/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0836 - accuracy: 0.9775 - val_loss: 0.0890 - val_accuracy: 0.9720
Epoch 5/50
157/157 [==============================] - 2s 13ms/step - loss: 0.0669 - accuracy: 0.9824 - val_loss: 0.0840 - val_accuracy: 0.9744
Epoch 6/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0559 - accuracy: 0.9848 - val_loss: 0.0831 - val_accuracy: 0.9756
Epoch 7/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0455 - accuracy: 0.9888 - val_loss: 0.0854 - val_accuracy: 0.9744
Epoch 8/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0406 - accuracy: 0.9899 - val_loss: 0.0846 - val_accuracy: 0.9742
Epoch 9/50
157/157 [==============================] - 2s 15ms/step - loss: 0.0340 - accuracy: 0.9917 - val_loss: 0.0859 - val_accuracy: 0.9769
Epoch 10/50
157/157 [==============================] - 3s 19ms/step - loss: 0.0300 - accuracy: 0.9920 - val_loss: 0.0927 - val_accuracy: 0.9740
Epoch 11/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0277 - accuracy: 0.9938 - val_loss: 0.0939 - val_accuracy: 0.9769
Epoch 12/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0222 - accuracy: 0.9947 - val_loss: 0.1022 - val_accuracy: 0.9751
Epoch 13/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0223 - accuracy: 0.9943 - val_loss: 0.1067 - val_accuracy: 0.9731
Epoch 14/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0199 - accuracy: 0.9948 - val_loss: 0.1080 - val_accuracy: 0.9749
Epoch 15/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0184 - accuracy: 0.9947 - val_loss: 0.1170 - val_accuracy: 0.9727
Epoch 16/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0192 - accuracy: 0.9939 - val_loss: 0.1215 - val_accuracy: 0.9731
Epoch 17/50
157/157 [==============================] - 2s 12ms/step - loss: 0.0196 - accuracy: 0.9939 - val_loss: 0.1173 - val_accuracy: 0.9740
Epoch 18/50
157/157 [==============================] - 2s 12ms/step - loss: 0.0148 - accuracy: 0.9959 - val_loss: 0.1176 - val_accuracy: 0.9747
Epoch 19/50
157/157 [==============================] - 2s 12ms/step - loss: 0.0139 - accuracy: 0.9961 - val_loss: 0.1293 - val_accuracy: 0.9731
Epoch 20/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0134 - accuracy: 0.9957 - val_loss: 0.1301 - val_accuracy: 0.9742
Epoch 21/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0136 - accuracy: 0.9959 - val_loss: 0.1257 - val_accuracy: 0.9769
Epoch 22/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0092 - accuracy: 0.9975 - val_loss: 0.1325 - val_accuracy: 0.9760
Epoch 23/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0090 - accuracy: 0.9975 - val_loss: 0.1381 - val_accuracy: 0.9742
Epoch 24/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0087 - accuracy: 0.9973 - val_loss: 0.1426 - val_accuracy: 0.9751
Epoch 25/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0075 - accuracy: 0.9976 - val_loss: 0.1434 - val_accuracy: 0.9767
Epoch 26/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0072 - accuracy: 0.9978 - val_loss: 0.1552 - val_accuracy: 0.9751
Epoch 27/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0077 - accuracy: 0.9976 - val_loss: 0.1545 - val_accuracy: 0.9751
Epoch 28/50
157/157 [==============================] - 2s 12ms/step - loss: 0.0066 - accuracy: 0.9980 - val_loss: 0.1583 - val_accuracy: 0.9751
Epoch 29/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0078 - accuracy: 0.9976 - val_loss: 0.1636 - val_accuracy: 0.9744
Epoch 30/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0060 - accuracy: 0.9978 - val_loss: 0.1676 - val_accuracy: 0.9749
Epoch 31/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0056 - accuracy: 0.9985 - val_loss: 0.1894 - val_accuracy: 0.9713
Epoch 32/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0134 - accuracy: 0.9949 - val_loss: 0.1658 - val_accuracy: 0.9753
Epoch 33/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0068 - accuracy: 0.9976 - val_loss: 0.1687 - val_accuracy: 0.9747
Epoch 34/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0076 - accuracy: 0.9976 - val_loss: 0.1684 - val_accuracy: 0.9744
Epoch 35/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0056 - accuracy: 0.9981 - val_loss: 0.1744 - val_accuracy: 0.9749
Epoch 36/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0061 - accuracy: 0.9978 - val_loss: 0.1769 - val_accuracy: 0.9736
Epoch 37/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0103 - accuracy: 0.9964 - val_loss: 0.1820 - val_accuracy: 0.9729
Epoch 38/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0078 - accuracy: 0.9978 - val_loss: 0.1898 - val_accuracy: 0.9718
Epoch 39/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0032 - accuracy: 0.9991 - val_loss: 0.1719 - val_accuracy: 0.9760
Epoch 40/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0102 - accuracy: 0.9962 - val_loss: 0.1995 - val_accuracy: 0.9711
Epoch 41/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0058 - accuracy: 0.9980 - val_loss: 0.1784 - val_accuracy: 0.9744
Epoch 42/50
157/157 [==============================] - 2s 12ms/step - loss: 0.0046 - accuracy: 0.9985 - val_loss: 0.1738 - val_accuracy: 0.9767
Epoch 43/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0055 - accuracy: 0.9980 - val_loss: 0.1806 - val_accuracy: 0.9758
Epoch 44/50
157/157 [==============================] - 2s 12ms/step - loss: 0.0031 - accuracy: 0.9991 - val_loss: 0.1852 - val_accuracy: 0.9744
Epoch 45/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0040 - accuracy: 0.9988 - val_loss: 0.1853 - val_accuracy: 0.9744
Epoch 46/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0030 - accuracy: 0.9990 - val_loss: 0.1950 - val_accuracy: 0.9738
Epoch 47/50
157/157 [==============================] - 2s 12ms/step - loss: 0.0015 - accuracy: 0.9996 - val_loss: 0.1996 - val_accuracy: 0.9742
Epoch 48/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0152 - accuracy: 0.9952 - val_loss: 0.1923 - val_accuracy: 0.9733
Epoch 49/50
157/157 [==============================] - 2s 12ms/step - loss: 0.0067 - accuracy: 0.9973 - val_loss: 0.1744 - val_accuracy: 0.9744
Epoch 50/50
157/157 [==============================] - 2s 11ms/step - loss: 0.0039 - accuracy: 0.9987 - val_loss: 0.1931 - val_accuracy: 0.9731
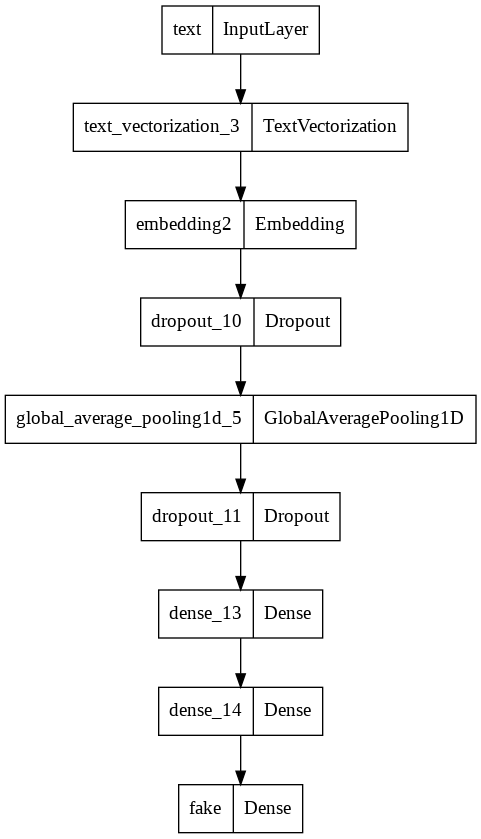
Let’s look at the flow of our model
utils.plot_model(model2)
Finally, let’s plot its performance on the validation set.
history_plot()
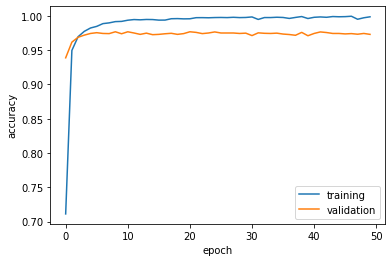
Once again, looks pretty good! We see there is about a consistent 97% accuracy! For our last model, we will take into account both the titles and the text when we construct our model. We predict that this will be our most accurate model yet.
Model 3
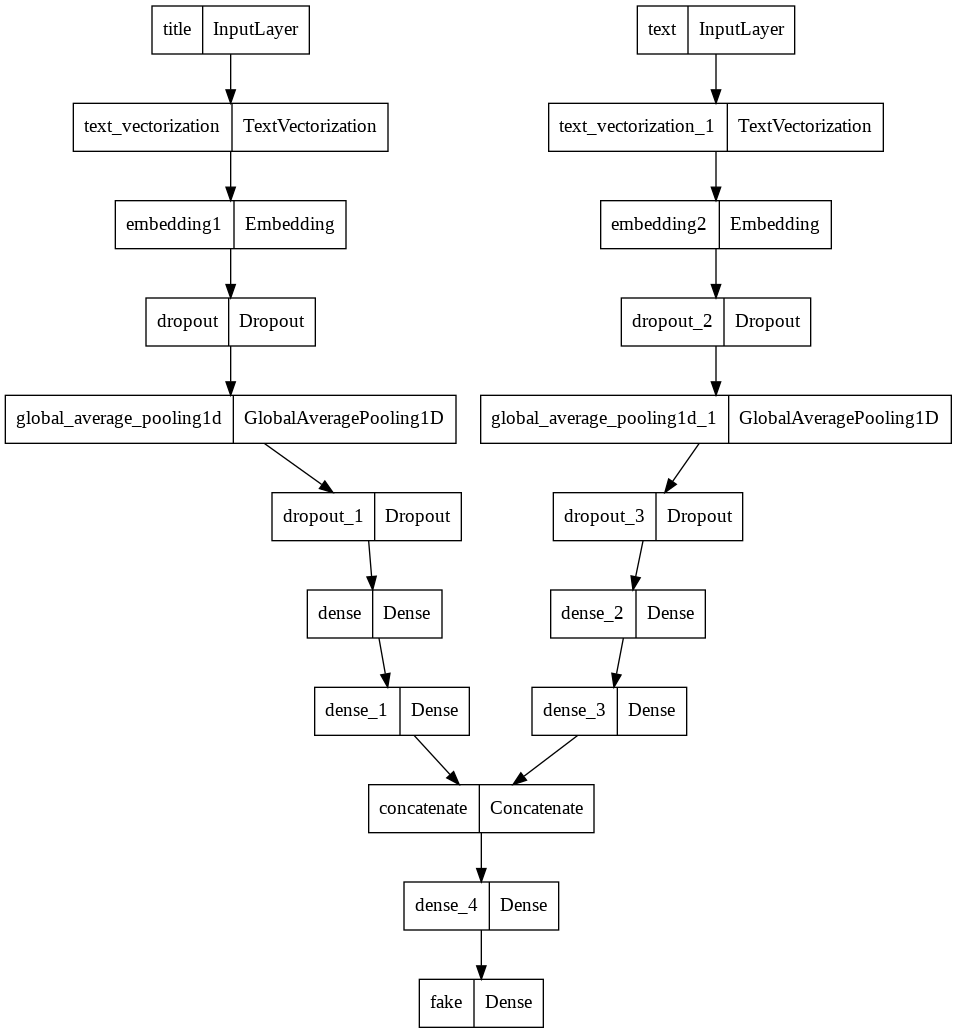
In the third model, we will use both the article title and the article text as input. Now we can combine the two models using layers.concatenate.
title_features = title_features
text_features = text_features
# combine text and title
main = layers.concatenate([title_features, text_features], axis = 1)
# output
main = layers.Dense(32, activation='relu')(main)
output = layers.Dense(2, name = "fake")(main)
model3 = keras.Model(
inputs = [title_input, text_input],
outputs = output
)
Now we have to fit our model to our training set.
model3.compile(optimizer="adam",
loss = losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"])
history = model3.fit(train,
validation_data=val,
epochs = 50,
verbose = 1)
Epoch 1/50
157/157 [==============================] - 6s 26ms/step - loss: 7.4767e-04 - accuracy: 0.9998 - val_loss: 0.0537 - val_accuracy: 0.9911
Epoch 2/50
157/157 [==============================] - 2s 14ms/step - loss: 4.1076e-05 - accuracy: 1.0000 - val_loss: 0.0554 - val_accuracy: 0.9911
Epoch 3/50
157/157 [==============================] - 2s 14ms/step - loss: 0.0034 - accuracy: 0.9990 - val_loss: 0.0511 - val_accuracy: 0.9884
Epoch 4/50
157/157 [==============================] - 2s 14ms/step - loss: 7.2481e-04 - accuracy: 0.9998 - val_loss: 0.0735 - val_accuracy: 0.9873
Epoch 5/50
157/157 [==============================] - 2s 14ms/step - loss: 0.0012 - accuracy: 0.9997 - val_loss: 0.0553 - val_accuracy: 0.9889
Epoch 6/50
157/157 [==============================] - 2s 14ms/step - loss: 0.0023 - accuracy: 0.9992 - val_loss: 0.0312 - val_accuracy: 0.9944
Epoch 7/50
157/157 [==============================] - 2s 13ms/step - loss: 5.4093e-04 - accuracy: 0.9998 - val_loss: 0.0846 - val_accuracy: 0.9851
Epoch 8/50
157/157 [==============================] - 2s 13ms/step - loss: 0.0012 - accuracy: 0.9996 - val_loss: 0.0483 - val_accuracy: 0.9916
Epoch 9/50
157/157 [==============================] - 2s 13ms/step - loss: 5.4437e-04 - accuracy: 0.9999 - val_loss: 0.0882 - val_accuracy: 0.9844
Epoch 10/50
157/157 [==============================] - 2s 13ms/step - loss: 0.0029 - accuracy: 0.9991 - val_loss: 0.0457 - val_accuracy: 0.9900
Epoch 11/50
157/157 [==============================] - 2s 14ms/step - loss: 3.9874e-04 - accuracy: 0.9999 - val_loss: 0.0358 - val_accuracy: 0.9933
Epoch 12/50
157/157 [==============================] - 2s 13ms/step - loss: 3.0234e-04 - accuracy: 0.9999 - val_loss: 0.0313 - val_accuracy: 0.9944
Epoch 13/50
157/157 [==============================] - 2s 13ms/step - loss: 6.8990e-04 - accuracy: 0.9997 - val_loss: 0.1000 - val_accuracy: 0.9820
Epoch 14/50
157/157 [==============================] - 2s 13ms/step - loss: 8.4658e-04 - accuracy: 0.9997 - val_loss: 0.0707 - val_accuracy: 0.9860
Epoch 15/50
157/157 [==============================] - 2s 14ms/step - loss: 0.0022 - accuracy: 0.9994 - val_loss: 0.0469 - val_accuracy: 0.9904
Epoch 16/50
157/157 [==============================] - 2s 13ms/step - loss: 6.7228e-04 - accuracy: 0.9998 - val_loss: 0.0715 - val_accuracy: 0.9858
Epoch 17/50
157/157 [==============================] - 2s 13ms/step - loss: 0.0028 - accuracy: 0.9989 - val_loss: 0.0495 - val_accuracy: 0.9889
Epoch 18/50
157/157 [==============================] - 2s 14ms/step - loss: 2.8878e-04 - accuracy: 0.9999 - val_loss: 0.0526 - val_accuracy: 0.9887
Epoch 19/50
157/157 [==============================] - 2s 13ms/step - loss: 1.4654e-04 - accuracy: 1.0000 - val_loss: 0.0458 - val_accuracy: 0.9909
Epoch 20/50
157/157 [==============================] - 2s 13ms/step - loss: 4.1262e-04 - accuracy: 0.9998 - val_loss: 0.0576 - val_accuracy: 0.9891
Epoch 21/50
157/157 [==============================] - 2s 13ms/step - loss: 0.0014 - accuracy: 0.9996 - val_loss: 0.0475 - val_accuracy: 0.9907
Epoch 22/50
157/157 [==============================] - 2s 14ms/step - loss: 0.0028 - accuracy: 0.9988 - val_loss: 0.0741 - val_accuracy: 0.9840
Epoch 23/50
157/157 [==============================] - 2s 14ms/step - loss: 8.8363e-04 - accuracy: 0.9996 - val_loss: 0.0386 - val_accuracy: 0.9909
Epoch 24/50
157/157 [==============================] - 2s 13ms/step - loss: 0.0013 - accuracy: 0.9997 - val_loss: 0.0514 - val_accuracy: 0.9898
Epoch 25/50
157/157 [==============================] - 2s 14ms/step - loss: 3.1105e-04 - accuracy: 0.9998 - val_loss: 0.0728 - val_accuracy: 0.9851
Epoch 26/50
157/157 [==============================] - 2s 14ms/step - loss: 2.5246e-04 - accuracy: 1.0000 - val_loss: 0.0543 - val_accuracy: 0.9893
Epoch 27/50
157/157 [==============================] - 2s 14ms/step - loss: 0.0013 - accuracy: 0.9994 - val_loss: 0.0801 - val_accuracy: 0.9820
Epoch 28/50
157/157 [==============================] - 2s 13ms/step - loss: 0.0013 - accuracy: 0.9996 - val_loss: 0.0427 - val_accuracy: 0.9907
Epoch 29/50
157/157 [==============================] - 2s 14ms/step - loss: 8.0247e-04 - accuracy: 0.9997 - val_loss: 0.0476 - val_accuracy: 0.9900
Epoch 30/50
157/157 [==============================] - 2s 13ms/step - loss: 4.1942e-04 - accuracy: 0.9998 - val_loss: 0.0633 - val_accuracy: 0.9873
Epoch 31/50
157/157 [==============================] - 2s 13ms/step - loss: 0.0018 - accuracy: 0.9995 - val_loss: 0.0324 - val_accuracy: 0.9929
Epoch 32/50
157/157 [==============================] - 2s 14ms/step - loss: 1.8973e-04 - accuracy: 1.0000 - val_loss: 0.0326 - val_accuracy: 0.9938
Epoch 33/50
157/157 [==============================] - 2s 14ms/step - loss: 9.3997e-04 - accuracy: 0.9996 - val_loss: 0.0384 - val_accuracy: 0.9929
Epoch 34/50
157/157 [==============================] - 2s 14ms/step - loss: 3.5687e-04 - accuracy: 0.9999 - val_loss: 0.0792 - val_accuracy: 0.9851
Epoch 35/50
157/157 [==============================] - 2s 13ms/step - loss: 0.0017 - accuracy: 0.9995 - val_loss: 0.0371 - val_accuracy: 0.9931
Epoch 36/50
157/157 [==============================] - 2s 13ms/step - loss: 0.0020 - accuracy: 0.9994 - val_loss: 0.0430 - val_accuracy: 0.9918
Epoch 37/50
157/157 [==============================] - 2s 14ms/step - loss: 0.0021 - accuracy: 0.9994 - val_loss: 0.0463 - val_accuracy: 0.9922
Epoch 38/50
157/157 [==============================] - 2s 13ms/step - loss: 0.0011 - accuracy: 0.9997 - val_loss: 0.0756 - val_accuracy: 0.9847
Epoch 39/50
157/157 [==============================] - 2s 14ms/step - loss: 0.0011 - accuracy: 0.9996 - val_loss: 0.0576 - val_accuracy: 0.9884
Epoch 40/50
157/157 [==============================] - 2s 13ms/step - loss: 5.3687e-04 - accuracy: 0.9999 - val_loss: 0.1249 - val_accuracy: 0.9804
Epoch 41/50
157/157 [==============================] - 2s 14ms/step - loss: 3.8168e-04 - accuracy: 0.9999 - val_loss: 0.0524 - val_accuracy: 0.9922
Epoch 42/50
157/157 [==============================] - 2s 13ms/step - loss: 8.7413e-04 - accuracy: 0.9997 - val_loss: 0.1130 - val_accuracy: 0.9836
Epoch 43/50
157/157 [==============================] - 2s 13ms/step - loss: 0.0013 - accuracy: 0.9996 - val_loss: 0.0359 - val_accuracy: 0.9933
Epoch 44/50
157/157 [==============================] - 2s 13ms/step - loss: 0.0015 - accuracy: 0.9994 - val_loss: 0.0876 - val_accuracy: 0.9851
Epoch 45/50
157/157 [==============================] - 2s 14ms/step - loss: 0.0011 - accuracy: 0.9998 - val_loss: 0.0893 - val_accuracy: 0.9833
Epoch 46/50
157/157 [==============================] - 2s 13ms/step - loss: 4.5296e-04 - accuracy: 0.9998 - val_loss: 0.1328 - val_accuracy: 0.9771
Epoch 47/50
157/157 [==============================] - 2s 13ms/step - loss: 4.0214e-04 - accuracy: 0.9999 - val_loss: 0.0384 - val_accuracy: 0.9933
Epoch 48/50
157/157 [==============================] - 2s 13ms/step - loss: 4.2899e-04 - accuracy: 0.9999 - val_loss: 0.0517 - val_accuracy: 0.9918
Epoch 49/50
157/157 [==============================] - 2s 14ms/step - loss: 0.0026 - accuracy: 0.9990 - val_loss: 0.0392 - val_accuracy: 0.9922
Epoch 50/50
157/157 [==============================] - 2s 14ms/step - loss: 0.0018 - accuracy: 0.9994 - val_loss: 0.0429 - val_accuracy: 0.9927
Let’s look at the flow of our model
utils.plot_model(model3)
Finally, let’s plot its performance on the validation set.
history_plot()
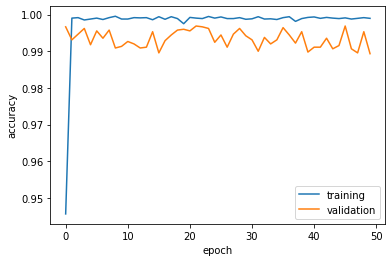
WOW! This our best Model with around a consistent 99% accuracy!! Now lets test our models on the test data.
§4. Model Evaluation
Now let’s test our models performance on unseen test data.
test_url = "https://github.com/PhilChodrow/PIC16b/blob/master/datasets/fake_news_test.csv?raw=true" #import test data
test_pd = pd.read_csv(train_url, index_col = 0)
test_data = make_dataset(test_pd)
loss1, accuracy1 = model1.evaluate(test_data)
print('Test accuracy for Model 1 :', accuracy1)
loss2, accuracy2 = model2.evaluate(test_data)
print('Test accuracy for Model 2 :', accuracy2)
loss3, accuracy3 = model3.evaluate(test_data)
print('Test accuracy for Model 3 :', accuracy3)
225/225 [==============================] - 1s 3ms/step - loss: 0.0479 - accuracy: 0.9881
Test accuracy for Model 1 : 0.9880618453025818
225/225 [==============================] - 2s 8ms/step - loss: 0.1199 - accuracy: 0.9760
Test accuracy for Model 2 : 0.9759899973869324
225/225 [==============================] - 2s 9ms/step - loss: 0.0126 - accuracy: 0.9968
Test accuracy for Model 3 : 0.9968372583389282
We see that the test accuracy for Model3 is 99.68% which is expected since it is our best model.
§5. Embedding Visualization
Our final step is to visualize the embeddings using PCA to reduce the features to 2-dimensional weights and take a closer look at some of the words that were most associated with fake news articles.
weights = model3.get_layer('embedding1').get_weights()[0] # get the weights from the embedding layer
vocab = title_vectorize_layer.get_vocabulary() # get the vocabulary from our data prep for later
from sklearn.decomposition import PCA
pca = PCA(n_components=2) # Convert our data into 2 dimensions
weights = pca.fit_transform(weights)
# visualzing the text embedding
embedding_df = pd.DataFrame({
'word' : vocab,
'x0' : weights[:,0],
'x1' : weights[:,1]
})
import plotly.express as px
fig = px.scatter(embedding_df,
x = "x0",
y = "x1",
size = [2]*len(embedding_df),
# size_max = 2,
hover_name = "word")
fig.show()
The words that are far from the orgin suggests strong indication towards fake or true news. On the negative x-axis side we have “spokesman” and “factbox” while the “breaking” and “just” and “hollywood” is on the postive x-axis side. It seems to me that the negative x-axis holds words that indicate a true article while the positive x-axis holds words that indicate a fake article.