
Movie and TV Show Recomendations
In this blog post, I will be using the Scrapy Python package to extract data from the IMDB website. I will build a simple recommendation system that will recommend movies or TV shows based on the number of actors a title shares with my favorite TV show, Friends.
§1. Setup
§1.1 Locate the Starting IMDB Page
Pick your favorite movie or TV show, and locate its IMDB page. For example, my favorite TV show is Friends. Its IMDB page is at:
https://www.imdb.com/title/tt0108778/
Save this URL for a moment.
§1.2 Here’s how we set up your scrapy project
- Create a new GitHub repository, and sync it with GitHub Desktop. This repository will house your scraper. You should commit and push each time you make significant changes to your code.
Here’s a link to my project repository
https://github.com/EGZJ17/IMDB-Scrapy- - Open a terminal in the location of your repository on your laptop, and type:
conda activate PIC16B scrapy startproject IMDB_scraper cd IMDB_scraperThis will create quite a lot of files, but you don’t really need to touch most of them.
§2. Write Your Scraper
Create a file inside the spiders directory called imdb_spider.py. Add the following lines to the file:
import scrapy
class ImdbSpider(scrapy.Spider):
name = 'imdb_spider'
start_urls = ['hhttps://www.imdb.com/title/tt0108778/']
Replace the entry of start_urls with the URL corresponding to your favorite movie or TV show.
§2.1 Now, implement three parsing methods for the ImdbSpider class.
- parse(self, response)
def parse(self,response): ''' A parsing method that navigates to its Cast and Crew page. ''' # Join current url with "fullcredits" full_credits = response.urljoin("fullcredits") yield scrapy.Request(full_credits, callback = self.parse_full_credits)This method works by starting on a movie or TV show’s home page, and then navigates to the Cast & Crew page. Once arrived at the full credits page, a second function,
parse_full_credits(self,response), is called in thecallbackargument ofscrapy.Request. - parse_full_credits(self, response)
def parse_full_credits(self,response): ''' A parsing method that navigates to each actor's page ''' # a list to get all urls to each actor's IMDB page actor_page_list = [a.attrib["href"] for a in response.css("td.primary_photo a")] # navigate to each actor's IMDB page for next_page in actor_page_list: next_page = response.urljoin(next_page) yield scrapy.Request(next_page, callback = self.parse_actor_page)In this method, we start on the Cast & Crew page and try to navigate through each actor’s page. The above list comprehension will create a list of relative paths, one for each actor. To find the url to the actor pages, we can make use of the web developer tool:
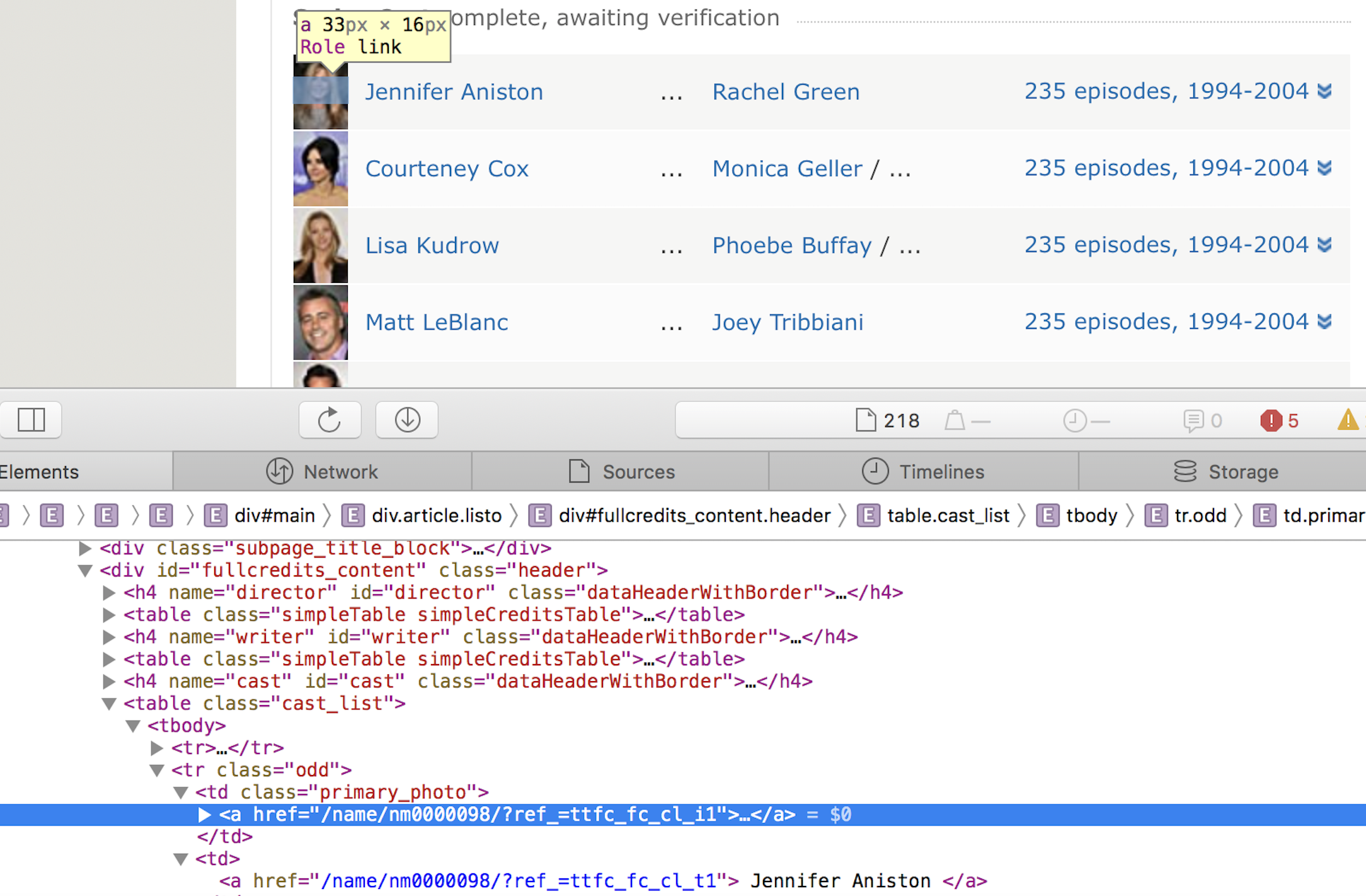 We see the url to the actor page is the
We see the url to the actor page is the "href"attribute inain the element"td.primary_photo a". This information can be extracted usingresponse.css. Once arrived at the actor’s page, the third functionparse_actor_page(self, response)is called, again in thecallbackargument ofscrapy.Request. - parse_actor_page(self, response)
def parse_actor_page(self, response): ''' A parsing method to get all movies and TV shows that an actor is listed in and put in dictionary. ''' #get actor name actor_name = response.css("h1.header").css("span.itemprop::text").get() # use set to avoid multiple entries movie_or_TV_list = set([a.get() for a in response.css("div.filmo-row b").css("a::text")]) #yield dictionary for a in movie_or_TV_list: movie_or_TV_name = a yield {"actor" : actor_name, "movie_or_TV_name" : movie_or_TV_name}To write this method, we start on the page of the actor. This method yields a dictionary with two key-value pairs, of the form
{"actor" : actor_name, "movie_or_TV_name" : movie_or_TV_name}. The method yields one such dictionary for each of the movies or TV shows on which that actor has worked. To get the actor’s name and what they worked on, we need the web developer tool: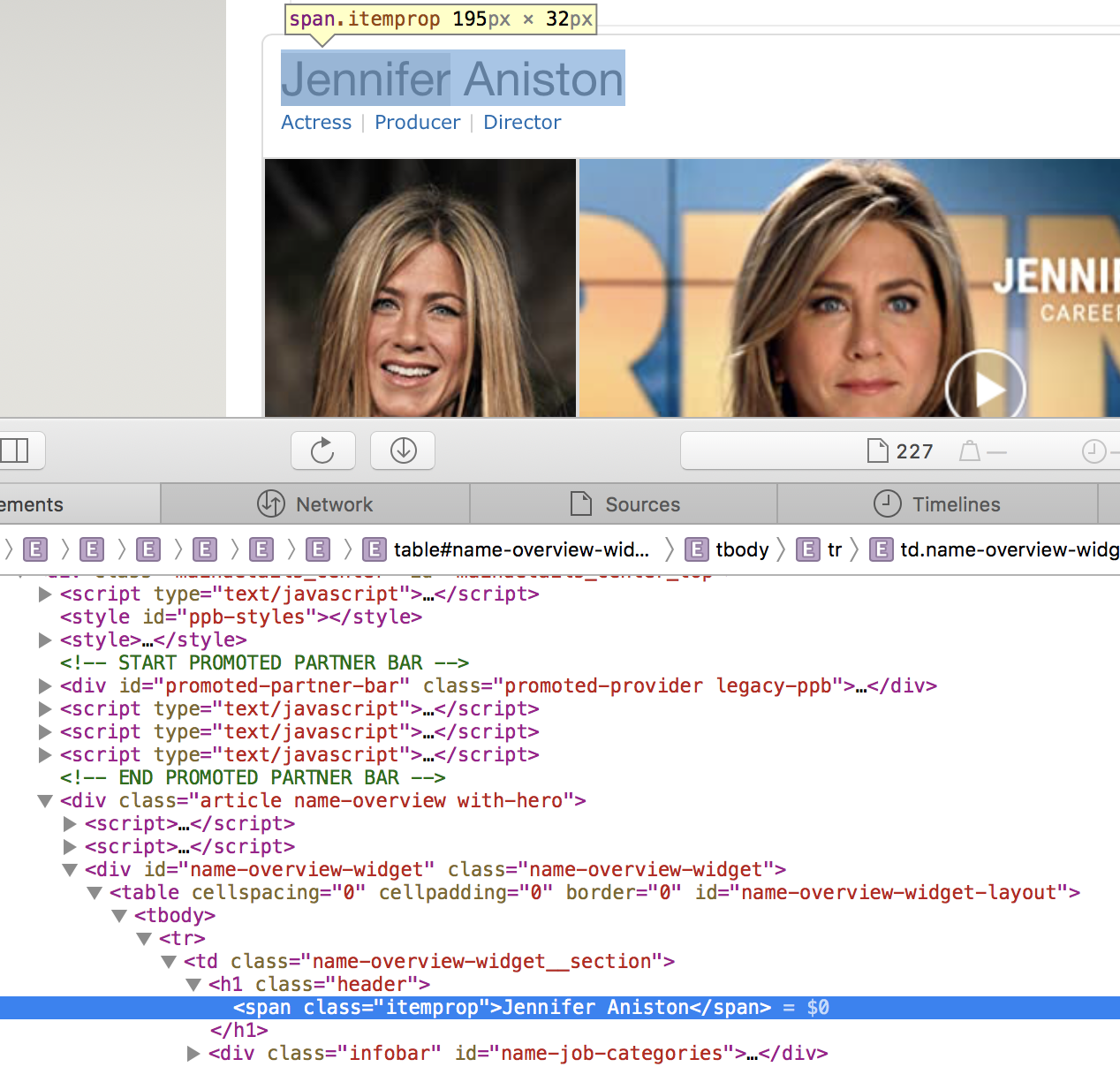 We see the
We see the actor_nameis in the class"h1.header span.itemprop"
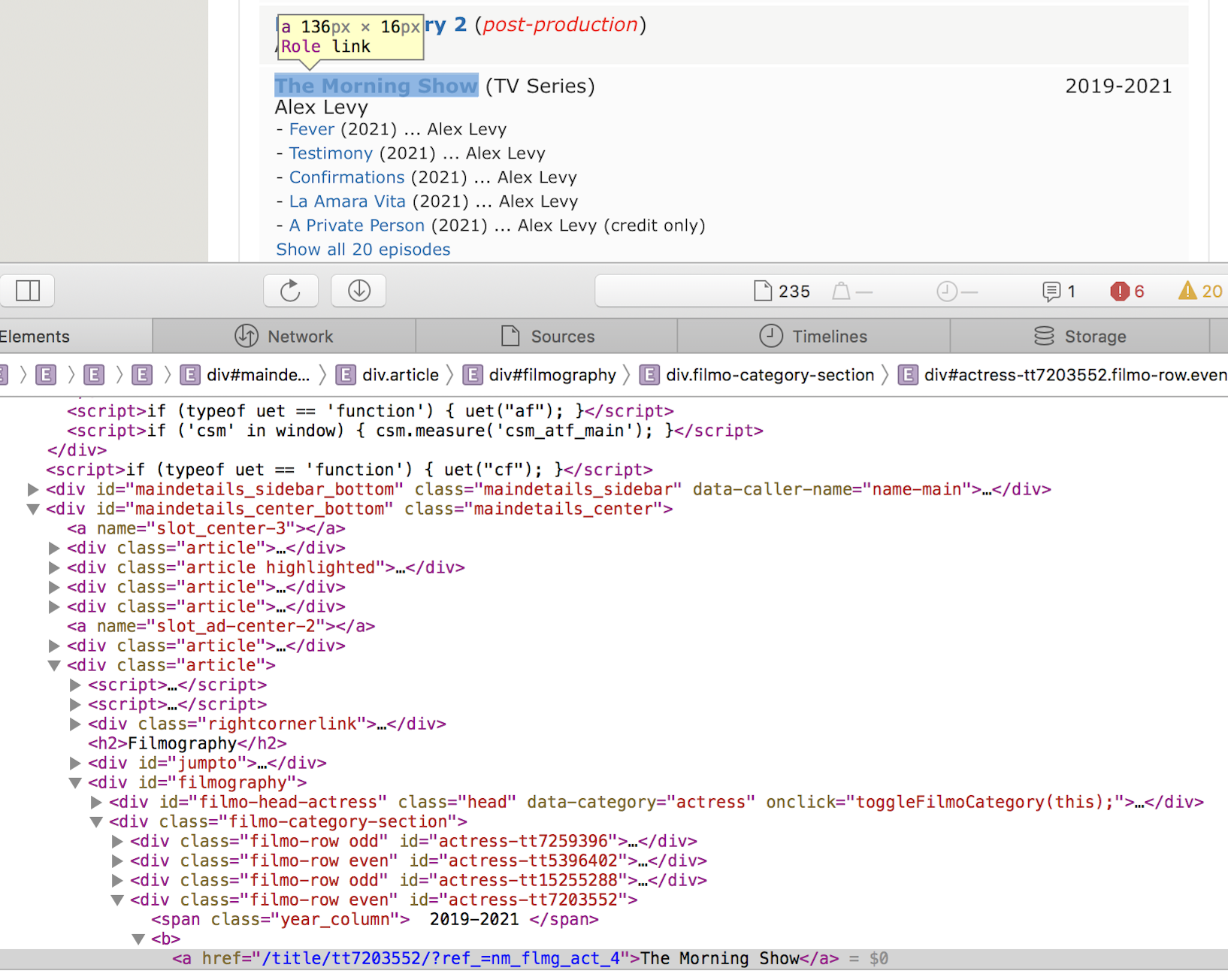 We see the
We see the movie_or_TV_name is in "div.filmo-row b a" element.
We use the .get() method since they both contain text information. We use set() to avoid multiple entries when the actors also are apart of movies or tv shows as other occupations besides acting, such as directing or producing. Then we yield our desired dictionary.
§ 2.2 Now our spider is ready!
Now, you can run the command in the terminal
scrapy crawl imdb_spider -o results.csv
to create a .csv file with a column for actors and a column for movies and TV shows.
§3. Make the Recommendations
Now let’s compute a sorted list with the top movies and TV shows that share actors with my favorite TV show, Friends! Since our data in a csv file, we need to do some cleaning so that we can visualize our results.
First let’s import pandas and read results.csv as a pandas data frame:
import pandas as pd
# read results.csv
results = pd.read_csv("results.csv")
Now, we need to convert the movie_or_TV_name column to a set to avoid multiple entries and then change it back to a list in order to iterate over it. Then, we need to count the number of times the movie or TV name has appeared in the results data frame by using .sum() method, and record the numbers with list comprehension:
# convert to set to avoid multiple entries and back to list for iterable
mov_li = list(set(results["movie_or_TV_name"].tolist()))
# record the number of shared actors by list comprehension
num_actors = [(results.movie_or_TV_name == movie).sum() for movie in mov_li]
Lastly, we will make a new dataframe with the movie or TV Show and number of shared actors. We will also sort by descending order:
# put data from dictionary in a pandas dataframe
df = pd.DataFrame(data={"movie or TV show":mov_li, "number of shared actors":num_actors})
# sort by descending order
df = rec.sort_values(by="number of shared actors", ascending=False )
#reassign the index
df = df.reset_index()
df = df.drop("index", axis =1)
# Show the top 20 recommedations
df.head(20)
| movie or TV show | number of shared actors | |
|---|---|---|
| 0 | Friends | 823 |
| 1 | ER | 182 |
| 2 | Entertainment Tonight | 136 |
| 3 | CSI: Crime Scene Investigation | 135 |
| 4 | Seinfeld | 122 |
| 5 | Today | 116 |
| 6 | NCIS | 114 |
| 7 | The Tonight Show with Jay Leno | 110 |
| 8 | NYPD Blue | 105 |
| 9 | Jimmy Kimmel Live! | 103 |
| 10 | Criminal Minds | 95 |
| 11 | Grey's Anatomy | 93 |
| 12 | Late Night with Conan O'Brien | 92 |
| 13 | Diagnosis Murder | 92 |
| 14 | Days of Our Lives | 90 |
| 15 | The West Wing | 87 |
| 16 | Celebrity Page | 86 |
| 17 | The Drew Carey Show | 85 |
| 18 | Charmed | 84 |
| 19 | Without a Trace | 83 |
Now, we have a clear list of movies and tv shows based on the number of shared actors on Friends!
We can also use plotly to display the results
First you need to import the following packages by running the following code:
from plotly import express as px
Let’s Plot a Histogram (the x-axis represents the name of each movieor TV Show and the y-axis represents the number of shared actors). Run the following code:
fig = px.histogram(df,
x = "movie or TV show",
y = "number of shared actors",
width = 600,
height = 300)
fig.update_layout(margin={"r":30,"t":170,"l":0,"b":0})
fig.show()
We see of course that Friends has the most amount of shared actors, which makes sense!